クラスタリング
ここではサーバーのクラスタリングを扱う。
フェイルオーバークラスター
障害(フェイル)が起きても、サービスを継続して提供できるように構成されるのがフェイルオーバークラスターである。
ホットスタンバイとコールドスタンバイ
待機系のサーバーの電源を落とした状態にしておくのが、コールドスタンバイである。
待機系のサーバーで、アプリケーションのロードまで行っているのがホットスタンバイである。フェイルが発生しても、システム全体としてサービスを停止することがない。
待機系をOSのロードまででとどめておくのを、ウォームスタンバイと呼ぶ。
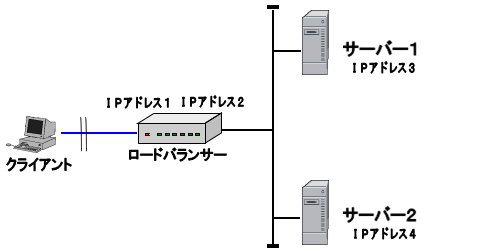
フェイルオーバー構成の例(1):ロードバランサーを使用した構成
2台(以上)のサーバーとクライアントの間に、ロードバランサーを設置し、ロードバランサーがアクセスすべきサーバーを決定する構成。
クライアントはロードバランサーのクライアントネットワーク側に設定されたIPアドレス(IPアドレス1)を使用してサーバーにアクセスする。この時クライアントは、サーバー1、サーバー2のどちらにアクセスしているのかを意識する必要がない。
次の2つの構成が考えられる。
正常時にサーバー1、サーバー2で負荷分散を行う。
メリット
サーバー1、サーバー2とも正常時に稼動させるため、資源が有効活用できる。
デメリット
どちらかのサーバーがダウンした場合、システム全体としてパフォーマンスが劣化する。最悪の場合はタイムアウトが頻発し、サービス提供が困難となり、実質的に冗長構成の意味を成さなくなってしまう。
正常時は一方のサーバーを待機系として業務に使用しない。
メリット
正常系と待機系で同じマシンスペックであれば、フェイルオーバー時もパフォーマンスの劣化を抑えることができる。
デメリット
待機系もアクティブスタンバイにしておく必要があり、正常時にはコスト(ソフトウェアライセンス、電力費等)が発生するにも関わらず、業務上の利益を生まない資産となってしまう。
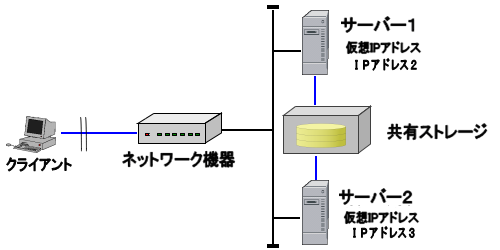
フェイルオーバー構成の例(2):仮想IP(VIP)アドレスを使用した構成
正常系と待機系の両サーバーに共通のIPアドレス(仮想IPアドレス)を割り当て、正常系がダウンした際に待機系が同じIPアドレスで処理を引き継ぐ方式である。
クラスターを実現するためのソフト=クラスタリングソフトを使用して、正常系サーバーの死活監視とフェイルオーバー処理を実行する。
各サーバーのネットワークカードには、仮想IPアドレスと実IPアドレスの2つが付与される。
正常系サーバーと待機系サーバーは共有ストレージによってアプリケーション領域やデータ領域を共有する。
正常系サーバーのダウンを検知すると、待機系サーバーは共有ストレージをマウントして、正常系サーバーの処理を引き継ぐ。
クライアントは常に仮想IPアドレスを使用してサービス要求を出し、サーバーのフェイルオーバーは意識する必要がない。
メリット
既存のネットワーク構成への影響が小さい。
システム全体でのデータの整合性が保ちやすい。
アプリケーション領域を共有ストレージに持ち、ある時点では常に一方のサーバーのみがアプリケーションを使用することで、ソフトウェア資産を抑制することができるケースがある。
デメリット
待機系のハードウェアは正常時には非稼動資産となってしまう。
フェイルオーバー構成の例(3):ブレードサーバーのN+1構成
ブレードサーバーを使用したN+1構成は、上記の仮想IPアドレスを使用して構成するケースの一つである。
単体サーバー(ブレードサーバーの対語)で構成するケースと比較すると、ハードウェアとそのユーティリティソフト、フェイルオーバー機能などをサーバーメーカーが一括で提供しているため、信頼性の高さが期待できる。
単体サーバーでは1つの通常系に対して1つの待機系サーバーを用意する必要があるのに対して、ブレードサーバーのN+1構成では複数の通常系に対して、1つの待機系を対応付けることができる。
ブレードサーバーでは管理コンソールを使用して、マシンの電源の投入/切断などを制御できるため、遠隔地からのフェイルオーバーの設定変更などが行える。
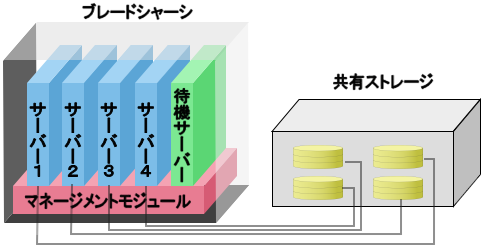
通常時
1つのブレードシャーシにサーバー1~4の4枚のサーバーブレードがインストールされている。
各サーバーは共有ストレージとSAN接続している。
各サーバーはOSも共有ストレージ内にインストールして、SANブートを構成している。
待機サーバーはコールドスタンバイになっている。
障害発生時
サーバー1~4のいずれかで障害が発生。ここではサーバー4とする。
ユーティリティソフトがサーバー4と共有ストレージの接続を切断し、待機サーバに接続する。
待機サーバーがアクティブになり、サーバー4のサービスを継続する。
製品例
負荷分散クラスター
サーバーのCPUやネットワークの負荷を分散することを目的とした構成である。
その他の負荷分散方法
クライアント側でサーバーのレスポンス向上を期待する場合は、キャッシュサーバーのようなものをクライアントの近辺に置くことがある。
大規模なWebサイトでは1つのURLで複数のサービスを提供している場合がある。各サービスは、さらに下位の負荷分散クラスタで処理されていることも多い。
クライアント側設定による負荷分散
クライアントのローカルにあるアドレス決定テーブル(UNIX系では/etc/hosts、Windowsでは/system32/drivers/hosts など)に接続するサーバーのエントリーを入れる。
サーバー側やネットワークでの追加投資を必要としない方法である。
運用上、IPアドレスの変更が必要になった場合に上記のアドレス決定テーブルを変更する必要がある。
頻繁にサーバーのIPアドレスが変わる場合や、不特定多数のクライアントを管理しなければならない場合には、設定変更や周知徹底の作業のボリュームが大きくなり、不向きな方法である。
ロードバランサーによる負荷分散
ロードバランサーは、様々な方法で負荷を分散する。
代表的なものを次に挙げる。なお、これらを組み合わせられるロードバランサー製品もある。
クライアントのIPアドレスやセグメントで接続先を決定
クライアントのローカルではなく、ロードバランサー側でクライアントのIPアドレスやセグメントで要求を振分ける。
サーバーのIPアドレスの変更が発生しても、ロードバランサーの設定を変更するのみで、クライアント側での設定変更は不要である。
サーバー側の負荷が考慮されないため、負荷が偏り、一部のユーザーからのみ、レスポンスに関する苦情が出る可能性がある。
ラウンドロビン方式
クライアントからの要求を順番にサーバーに割り当てる。
要求が来るごとにサーバーへの要求を単純に順番に割り当てるものや、サーバーの性能差などを考慮してシステム管理者が割振りに「重み付け」を行えるものなどがある。
サーバーとのコネクション数による決定
ロードバランサーとサーバー間で確立しているネットワークのコネクション数で、振分け先のサーバーを決定する。
本項で指すのは、サーバー側には何のソフトもインストールせず、単純にネットワークのレスポンスのみからサーバー側の状況を判断するタイプである。
サーバーからのレスポンス時間による決定
ロードバランサー側からサーバーに発した要求に対するレスポンス時間の統計に基づいて、振分け先のサーバーを決定する。
本項で指すのは、サーバー側には何のソフトもインストールせず、単純にネットワークのレスポンスのみからサーバー側の状況を判断するタイプである。
サーバー側の負荷を考慮して決定
サーバー側にロードバランサー用のソフトをインストールし、サーバー側のCPU負荷などの情報をロードバランサー本体とやり取りして、要求の振分け先を決定する。
製品例
Webサイトのセッション管理
HTTPはセッションを確立しない接続である。しかし、多くのWebサイト、特にECサイトではセッションを維持しなければならない。
HTTPでセッションを擬似的に維持するために、一般に次のような方法で実現する。
- Webアプリケーションサーバー(WAS)側でセッションIDを生成する。
- 接続してきたクライアント側にセッションIDを送信する。
- WASはクライアントがアクセスして来た際に、セッションIDを参照して、アクティブなセッションIDを自サーバーで持っていれば、同じセッションとして後続の処理を行う。
クライアントにセッションIDを渡す方法は次の方法をとる場合が多い。
- URLにクライアントIDとセッションIDを埋め込む。
- FORMのHIDDEN属性でクライアントにセッションIDを埋め込む。
- Cookieを使ってクライアントとセッションIDをやり取りする。
同じクライアントがサイトにアクセスした時に、WASがロードバランシングされていて、異なるサーバーに接続されてしまうとセッションが維持できなくなってしまう。この解決方法として、次のような方法がある。
- 同一のIPアドレスは常に同じサーバーに接続する。
- ロードバランサーでCookieを参照して、セッションIDを判別し、割振り先のWASを決定する。
- ロードバランサー専用の機器ではなく、サーバーにロードバランサー機能を搭載したWASをインストールして、接続を最適化する。
ソフトウェアによるクラスタ構成
Webアプリケーションサーバーによるクラスター構成
Webアプリケーションサーバーの機能として、ロードバランシングやキャッシュを行う含むものがある。
ロードバランサー専用機器を使用する場合に比べて、きめ細かなアクセスを振分けが可能である。
製品例
Oracle 10g R2 RACによるクラスター構成
RACは「Real Application Cluster」の略である。
RAC導入により期待できる効果は、サーバーのCPUがボトルネックになっているデータベース処理のパフォーマンス向上やサーバーのハードウェア障害、OSの障害などによる業務中断の防止である。
RACでは1つの共有ストレージを複数のサーバーで共有する。従って、共有ストレージで発生するメディア障害などには対応できない。
RACを構成している環境でのフェイルオーバーは高速で、かつデータの不整合、発生を抑止できる。そのため、2台のサーバーでRACを構成しても通常は一方のサーバーで処理を行い、もう一方は待機系として使用する使用例もある。